这个递归不太难
相信大家都知道什么是递归,但在实际开发的时候用过多少次递归呢?
程序的世界有句话叫“人用循环,神用递归”,很多情况下我们都会优先使用循环而不是递归。我和几个朋友聊过,他们的看法是:“相比循环而言,递归性能更差,而且更不可控,容易出问题。”
捕获关键词“问题”,启动“解决”模式…
一、先热个身
数学家高斯的在念小学的时候,他的数学老师出了一道题:对自然数1到100求和。高斯用首尾相加的办法很快的算出了答案,不过我们这次要扮演高斯的同学,老老实实的从1加到100。
首先试一下循环的思路:
function sum(n) {
let count = 0;
for (let i = 1; i <= n; i++) {
count += i;
}
return count;
}
sum(100); // 5050
可以看到循环体只有一行代码
count += i;
如果把 count 当成是一个函数的返回值,一个基本的递归逻辑就成型了:
function sum(n) {
return n + sum(n-1);
}
// 这里的 sum(n-1) 不能写成 sum(n--)
但仅仅这样是不够的,还差一个关键代码块——开关
递归本身是一个无限循环,需要添加控制条件,让程序在合适的时候退出循环
function sum(n) {
if (n === 1) {
return n;
}
return n + sum(n-1);
}
sum(100); // 5050
试试
sum(20000)的结果是多少?
二、三大要素
上面的例子已经完成了一个简单的递归,回头总结一下,我们主要做了两件事:
- 递归的拆解 —— 提取重复的逻辑,缩小问题规模
- 递归的出口 —— 明确递归的结束条件
其实在这之前,我们还做了一件事,这件事很重要,但常常会被我们忽略掉:
- 递归的定义 —— 明确函数的功能
这三大要素是写递归的必要条件,而其中的第三点,是写好一个递归的必要条件。
以经典的树组件作为案例,来印证一下这三要素。
树组件的主要功能,就是将一个规范的具有层级的数组,渲染成树列表

由此我们能明确这个函数的主要功能:接收一个数组入参,返回一个完整的树组件
好像大概可能应该也许有点问题?
还是先来观察数组吧。每个元素的 title 和 key 是固定的,只是非叶子节点有 children。而 children 内部的结构也是 title 和 key,加一个可能有的 children。
这样一来就能很容易的提取出重复的逻辑:渲染树节点,以 children 作为递归结束的判断条件。
为了更好的 UI 展示,还需要记录树节点的层级来计算当前节点的缩进。
我们只是在渲染树节点,而不是渲染整个树!
之所以能渲染出整个树,是因为在函数执行的过程中,产生了很多的树节点,这些树节点组成了一个树。
所以我们这个函数功能应该是:接收一个数组作为必要参数,和一个数值作为可选参数,并返回一个树节点。
重新捋一下思路,这个渲染树组件的函数就清晰多了:
renderTree = (list, level = 1) => {
return list.map(x => {
const { children, id } = x || {};
if (children) { // 递归的结束条件
return (
<TreeNode key={`${id}`} level={level}>
{/* 调用自身,形成递归 */}
{renderTreeNodes(children, level + 1)}
</TreeNode>
);
}
// 递归的出口
return <TreeNode key={`${id}`} level={level}></TreeNode>
})
}
三、递归优化 – 手动缓存
当我们去分析一个循环的时候,能清晰的看出这个函数的内部逻辑和执行次数。
而递归则不然,它的结构更加简洁,但也增加了理解成本。比如下面这个递归,你能一眼看出它的执行次数么?
function Fibonacci (n) {
return n <= 2 ? 1 : Fibonacci(n - 1) + Fibonacci(n - 2);
}
这就是著名的 Fibonacci 数列,我尽力避免拿它举例,后来发现这个例子最为简单直观。
Fibonacci 数列:1, 1, 2, 3, 5, 8, 13, 21…
f(n) = f(n-1) + f(n-2)
我们试着执行一下 Fibonacci(10),并记录该函数的调用次数
居然执行了 109 次?
其实回头分析一下 Fibonacci 这个函数就能发现,执行的时候存在很多的重复计算,比如计算 Fibonacci(5):
-- f(5)
| -- f(4)
| | -- f(3)
| | | -- f(2)
| | | -- f(1)
| | -- f(2)
| -- f(3)
| | -- f(2)
| | -- f(1)
叶子节点会被重复计算,层次越深,计算的次数就越多
这里有两个优化思路,第一种是从当前的逻辑上,添加一层缓存,如果当前入参已经计算过,就直接返回结果。
// 缓存函数
function memozi(fn){
const obj = {};
return function(n){
obj[n] = obj[n] || fn(n);
return obj[n];
}
}
const Fibonacci = memozi(function(n) {
return n <= 2 ? 1 : Fibonacci(n - 1) + Fibonacci(n - 2);
})
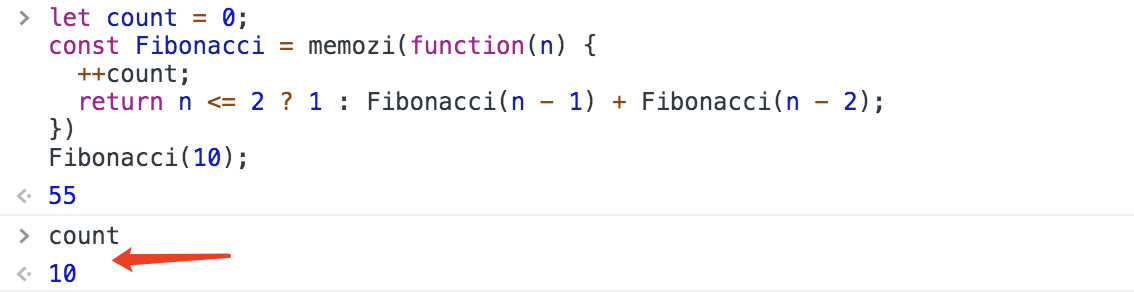
只执行了10次!这已经达到了循环的执行次数。
这是一种空间换时间的思想,增加了额外的变量来记录状态,不过函数的实际调用次数并没有减少,只是在 memozi 函数中做了判断。
怎么才能真正实现 O(n) 的时间复杂度呢?
四、递归优化 – 自下而上
上面所有的递归都是自上而下的递归,从 n 开始,一直计算到最小值。但在 Fibonacci 的例子中,如果需要计算 f(n),就需要先计算 f(n-1),所以一定会存在重复计算的情况。
能不能从最小值开始计算呢?
在明确了 f(n) = f(n-1) + f(n-2) 规则的前提下,同时又知道 f(1) = 1, f(2) = 1,那就能推断出 f(3) = 2,乃至 f(4), f(5)...
从而得到一个基本逻辑:
function foo(x = 1, y = 1) {
return foo(y, x + y);
}
这里的 x 和 y 就是对应 n=1 和 n=2 的时候的值,然后逐步计算出 n=3, n=4... 的值。
然后加入 n <= 2 的边界,得到最终的递归函数:
function Fibonacci(n, x = 1, y = 1) {
return n <= 2 ? y : Fibonacci(n - 1, y, x + y);
}
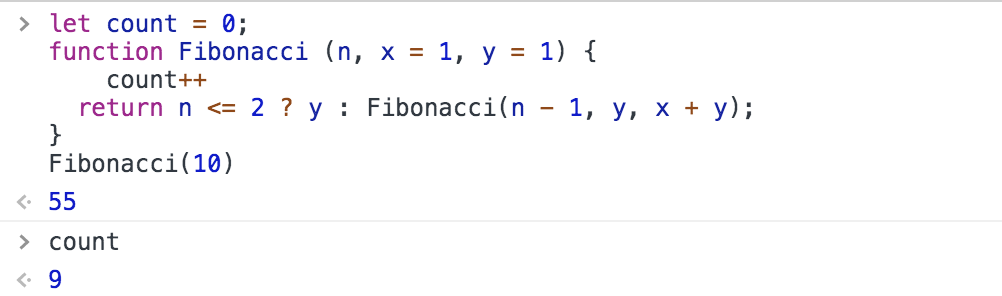
我们仅仅是稍微调整了函数的逻辑,就达到了 O(n) 的时间复杂度。这种自下而上的思想,其实是动态规划的体现。
动态规划是一种寻求最优解的数学方法,它经常会被当做一种算法,但它其实并不像“二分查找”、“冒泡排序”一样有着固定的范式。实际上动态规划是一种方法论,它提供的是一种解决问题的思路。
简单来说,动态规划将一个复杂的问题分解成若干个子问题,通过综合子问题的最优解来得到原问题的最优解。而且动态规划是自下而上求解,先计算子问题,再由这些子问题计算父问题,直至求解出原问题的解,将时间复杂度优化为 O(n)。
动态规划有三个重要概念:
- 最优子结构
- 边界
光看名词就觉得有点似曾相识。没错,这就是前文提到的递归三要素中的“缩小问题规模”和“结束条件”。
而动态规划的第三个概念,才是其核心所在:
- 状态转移方程
所谓状态转移方程,就是子问题与父问题之间的关系,或者说:如何用子问题推导出父问题。
通常我们用递归都是自上而下,是先遇到了父问题,再去解决子问题。而动态规划是先解决子问题,再通过状态转移方程求解出父问题,也就是自下而上。这种自下而上的递归也被称为“递推”。
动态规划的适用范围,也是自下而上的适用范围:
-
存在最优子结构
作为整个过程的最优策略,应当具有这样的特质:无论过去的状态和决策如何,相对于前面的决策所形成的状态而言,余下的决策序列必然构成最优子策略。
也就是说,一个最优策略的子策略也是最优的。
-
无后效性
如果某阶段状态给定后,则在这个阶段以后过程的发展不受这个阶段以前各段状态的影响。
也就是说,计算
f(i),不需要f(i+1)...f(n)的值,也不会修改f(1)...f(i-1)的值(1 < i < n)。
只要满足这两点,就可以用自下而上的思路来优化。
不过上面自下而上求解 Fibonacci 数列的函数,除了动态规划之外,还使用了尾调用。
五、递归优化 – 尾调用
函数在调用的时候,会在调用栈 (call stack) 中存有记录,每一条记录叫做一个调用帧 (call frame)。每调用一个函数,就向栈中 push 一条记录,函数执行结束后依次向外弹出,直到清空调用栈。
function foo () { console.log('wise'); }
function bar () { foo(); }
function baz () { bar(); }
baz();
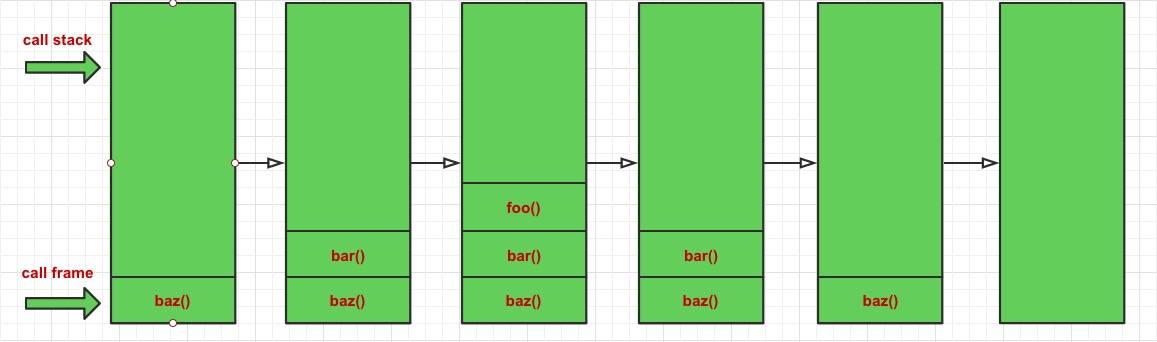
造成这种结果是因为每个函数在调用另一个函数的时候,并没有 return 该调用,所以 JS 引擎会认为你还没有执行完,会保留你的调用帧。
如果对上面的例子做如下修改:
function foo () { console.log('wise'); }
function bar () { return foo(); }
function baz () { return bar(); }
baz();
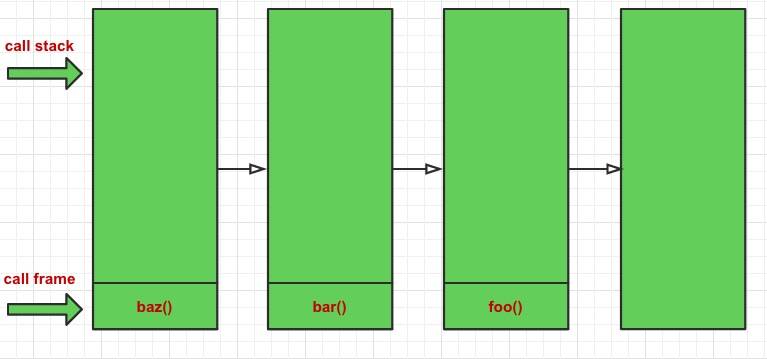
上面的改动其实是函数式编程中的一个重要概念,当一个函数执行时的最后一个步骤是返回另一个函数的调用,这就叫做尾调用(PTC)。如果是在递归里面使用,即在函数的末尾调用自身,就是尾递归。
回头来看最开始的求 1~n 之和的例子:
function sum(n) {
if (n === 1) {
return n;
}
return n + sum(n-1);
}
sum(100); // 5050
如果执行 sum(20000) 会栈溢出(爆栈):
Uncaught RangeError: Maximum call stack size exceeded
将这个递归升级为尾递归:
function sum(n, count = 0) {
if (n === 1) {
return count + n;
}
return sum(n-1, count+n);
}
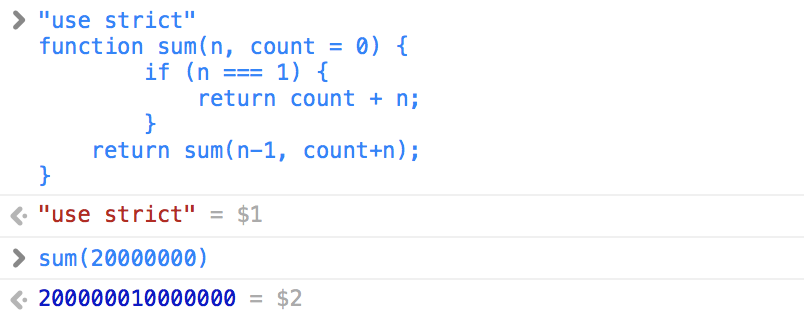
现在调用栈中的调用帧始终只有一条,相对节省内存,这样的递归就靠谱了许多
尾调用对递归的意义重大,但在实际运用的时候却备受阻碍。
首先需要使用严格模式"use strict",其次主流浏览器只有 Safari 支持尾调用(上面的截图就是在 Safari 截的),Chrome 和 Firefox 甚至 node 都不支持尾调用优化。
Chrome V8 团队给出的解释是:
- 由于尾调用消除调用帧是隐式的,这意味着开发者可能很难发现一些无限循环的递归,如果它们恰好出现在末尾,因为这些递归的堆栈将不再溢出。
- 尾调用会丢失堆栈信息,这将导致执行流中的堆栈信息丢失,这将影响程序调试和错误收集。
不过即使如此,Chrome 和 Mozilla 依然认可尾调用优化所带来的的性能提升,只是在引擎层面还没有找到一个很安全可靠的方案来支持尾调用优化。微软曾经提议从语法上来指定尾调用(类似于 return continue 这样的特殊语句),不过最终方案仍在讨论中。
虽然大部分的浏览器还不支持尾递归,但我们在开发的时候依然可以优先使用尾调用,毕竟运行的效果是一样的,而一旦程序在支持尾递归的环境下运行,就会有更快的运行速度。更重要的是,当我们尝试使用尾递归的时候,通常会自然而然的用到自下而上的思想。
六、小结
我们一般认为递归会比循环的性能要差,是因为函数调用本身是有开销的。
但如果能实现尾递归,那么递归的效率应该至少和循环一样好。
对于不能使用尾调用的递归,即使写成了循环的形式,也只是拿一个栈来模拟递归的过程。会带来一定的效率提升,但也会造成代码的冗余。
关于循环和(优化之后的)递归之间的取舍,我觉得可以从以下几个方面判断:
- 递归的优点是代码简洁,逻辑清晰。缺点是调用帧导致的执行效率过低,而且不如循环容易理解;
- 递归和循环完全可以互换,但递归可以处理的问题,如果通过循环去解决,通常需要额外的低效处理;
- 如果逻辑相对简单,使用循环也很简洁,可以优先考虑循环;
- 在无法使用尾递归的环境,循环永远是优先考虑的解决方案,但如果能接受递归的性能开销,建议使用递归。
我认为递归其实是一种思维方式。所谓的“递归比循环慢”,指的是递归的各种实现。
掌握递归的意义不在于编码本身,而在于知道如何编码。
Premature optimization is the root of all evil.
过早优化是万恶之源。
—— 《计算机编程艺术》Donald Knuth
参考资料:
《递归优化:尾调用和Memoization》—— LumiereXyloto
《尾调用优化》—— 阮一峰
《【译】V8 团队眼中的 ES6、ES7及未来》—— 奇舞团
《什么是动态规划(Dynamic Programming)?动态规划的意义是什么?》—— 苗华栋
1.《这个递归不太难》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《这个递归不太难》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.cxvn.com/study/26945.html